
[toc]
If you’re talking about the Japanese “alphabet” you’re stepping into some fraught waters.
First, as any internet pedant with a self-appointed PhD in Japan Cultural Studies will tell you, Japan doesn’t have an alphabet. It has a syllabary.
Two, in fact. Plus kanji (Chinese characters). Oh, and romaji, aka Roman letters.
That’s four writing systems in total, employed daily and in all walks of life by the Japanese.
What are these so-called “alphabets”? What do they look like? How do they work? Well, that’s what this article is all about.
By the end, you’ll know what the writing system looks like, how it’s used, what it’s called, and I’ll even send you off with some history about the long, strange development of Japan’s writing system.
But let’s start simple. Here’s the skinny:

What is the Japanese alphabet?
The so-called Japanese alphabet is made up of four writing systems; however, strictly speaking, none of them are true alphabets. There’s romaji (the same type of characters you’re reading now), kanji (Chinese characters), and then the syllabaries—hiragana and katakana—which are together known simply as kana. Kana are similar to letters in that they each represent a sound. There are 46 characters in hiragana and katakana each, with hiragana and katakana being mirrors of each other, similar to capital and lower case letters in English.
Starting Simple: Romaji
The only “real alphabet” used by Japanese is romaji. I put “real” and “alphabet” in quotes because, as mentioned, the kana are actually classified as syllabaries (we’ll get to what exactly that means in a moment) and kanji are logographs.
The extent of Romaji is the same as in English, with just 26 letters being required. Romaji are used for a variety of purposes.
They’re used for acronyms (like NASA, FBI, or JAXA), foreign names, foreign quotations, and as part of mixed-use words (for example, Tシャツ, “T-shatsu”).
Romaji are also used to write out personal and corporate names, especially when being printed for foreign use.
Beyond these explicitly practical uses, romaji are used to add a bit of flair to text.
Writing some of your ad in English or French imparts a bit of je ne sais quois, in the same way that adding a little French to English does. Many store names are written in romaji, as well as the names of bands and some films and TV shows.
And, finally, romaji are used to romanized Japanese words.
Do as the Romans…
There’s a handful of different romanization techniques out there, but I’ll focus on just the most well-known ones.
One of the earliest efforts can be found in the Nippo Jisho, a Japanese—Portuguese dictionary compiled in 1603.
There are some interesting forms of Japanese romanization in the text, but, unfortunately, when the Tokugawa regime took control of Japan a few years later, they kicked almost all Westerners out of the country, along with their romaji.
It wouldn’t be until the 19th century, when Japan once again opened up to the world, that techniques to romanize the language would begin again in earnest.
In fact, it was in such earnest that starting in the Meiji Period (1868-1912), people began proposing that the language be written entirely in romaji.
A few books apparently came out of this movement, but, luckily, it didn’t catch on.
For anyone who thinks abolishing kanji would actually be a good thing, wait until you get an email from a well-meaning Japanese person who does, in fact, write all in kana or romaji with the intention of being helpful.
If you can tell me the difference between “shuu,” “shuu,” “shuu,” “shuu,” “shuu,” “shuu,” “shuu,” “shuu,” “shuu,” “shuu,” “shuu,” “shuu,” and “shuu,” then by all means, be my guest.
King of the Romans-ji
The most well-known system for romanizing Japanese is the Hepburn system, developed in the late 19th century by an American missionary.
While it’s not the official form used by the Japanese government, Hepburn romanization is the standard worldwide since it most closely approximates Japanese sounds with regards to English and Romance-language spellings.
There’s a few variations within Hepburn (mostly related to vowel-lengthening), but on the whole it’s fairly cohesive and easy to get to grips with. It looks like this:
 https://en.wikipedia.org/wiki/Hepburn_romanization
https://en.wikipedia.org/wiki/Hepburn_romanization
Nihon-shiki romanization was an early contender to try and displace Hepburn.
It was developed in 1885 by a physicist from northern Japan in an attempt to make a system that would help Japan become more competitive on the international stage.
This system distinguishes itself by its emphasis on a highly regular, one-to-one connection between kana and the romanized form which made it easier for Japanese people to learn and use.
However, somewhat ironically, this makes it more difficult for foreigners to pronounce.
For example, the kana は is pronounced “ha” in every situation except when it’s used as a particle when it’s pronounced “wa.”
Hepburn adjusts for this, Nihon-shiki does not, choosing to render all cases of は as “ha.” This and many other forced regularities make Nihon-shiki a challenge for non-native readers.
Following this was Kunrei-shiki, an evolution of Nihon-shiki which was ordered by the 1937 Japanese government.
This system is still officially supported by the government, but, in practice, Hepburn continues to rule the day.
Kunrei-shiki is largely used by Japanese natives and linguists studying Japanese, since this romanization system is best adapted to displaying the nuances of Japanese grammar.
For a quick comparison, let’s take a look at the romanization of the word for “to shrink,” ちぢむ.
Hepburn — chijimu
Nihon — tidimu
Kunrei — tizimu
Roma-Digi
This one is a weird sorta-romanization. Wapuro-romaji (“wapuro” comes from “word processing”… you’ll have to use your imagination a bit to hear it) is the system used to write Japanese using a Western-style keyboard.
Wapuro inputs are standardized through the JIS (Japanese Industrial Standards) system of regulation which is handled by a committee under the control of the Ministry of Economy, Trade and Industry.
And, while the input is standardized, there is no single encoding standard, though UTF-8 is the most dominant these days.
When using a keyboard to input Japanese to a computer, Hepburn, Nihon-shiki, or Kunrei-shiki may be accepted, with some exceptions.
Overall, there’s a one-to-one connection between the kana character you want, and it’s romanized equivalent. Want が? Type G and A.
Some things that stand out as different from the romanization systems we mentioned before are necessary because of the limitations of the computer.
For example, if you want to type a small vowel by itself, you preface it with an “x”. So a > あ becomes xa > ぁ.
You’d, of course never write the “x” in any other romanization system.
Similarly, in order to type the ん character by itself, you’d need to tap the “n” key twice, while in any other romanization system it would only be written once.
Other divergences include things like は needing to always be typed as “ha,” even in cases where it’s used as a particle (i.e resulting in a “wa” pronunciation).
When typing Japanese, what will happen is that as you input each roman character, they will transform into their equivalent kana on the screen (either hiragana or katakana, depending on which you have enabled at the moment).
As the kana fill the screen, a box will drop down below your text with some predictive text options for the kanji you might want.
For example, ほうこう can become 方向, 芳香, 奉公, 放校, 咆哮, 放光, 縫工, 砲熕, 砲口, or 彷徨. When you type ほうこう, each of those kanji options will be in the drop down box, as well as common things that follow, like additional kanji, particles, or kana expressions.
As you type more kana, the predictive text narrows down until there’s only a few possible options.
It’s always very satisfying to type out a loooooong string of kana, then tap the tab key and watch the whole crazy string coalesce into a beautiful Japanese sentence.
Defining the Syllabary
So what’s this kana thing? Is that the alphabet?
Sorta. If you like internet arguments, go onto any Japanese forum and state that Japanese uses an alphabet made up of hiragana and katakana. Chaos shall ensue.
Half the people will be on your side, rushing to your defense in the name of simplicity and ease.
The other half, cherry-cheeked and hopping mad, will come swinging flails spiked with the words “syllabary” and “mora” as if swatting you in the face with such strange terms will help at all.
“Well, fine,” you think. “What the heck is a syllabary? And what the hell is a mora?”
A syllabary is a writing system made up of syllabograms.
“Okay, wise guy, what’s a syllabogram?” I hear you groan.
Well, a syllabogram represents one mora.
You’re shaking your fist at me. I can tell.
So, the definition of a mora is hard to pin down. However, it’s similar to a syllable.
In Japanese, a mora is a unit of sound, where each mora is counted as an individual sound, and is, in theory, given equal time.
So, from an English-speaking perspective, the words “o” and “oo” in Japanese would both be one syllable; however, in Japanese they’re two morae.
This means that the “o” sound in the second word is exactly twice as long as in the first one.
So, in Japanese each syllabogram represents one mora, and syllabograms are units of a syllabary.
Is there an important distinction to make between alphabet and syllabary? Eh. In my opinion, it’s more trivia than useful information.
The most important thing to keep in mind is that with the Japanese syllabary, each character equals one unchanging (again, in theory) unit of sound.
That is to say that, while in English the letter C can sometimes make an “s” sound and sometimes make a “k” sound (among others, in combination), in Japanese these sorts of changes can never happen (again, in theory—spoken Japanese is undertaken at your own peril).
The one thing that is useful to keep in mind is that Japanese is made up of a somewhat limited set of immutable sounds (again, again, again, in theory), each one comprising a single mora.
So, to Japanese ほ is one single unit of sound, while its romanization, being “ho”, seems to a native English speaker to be comprised of two sounds.
To conclude this section, keep in mind: The Japanese syllabary creates characters with a one-to-one relationship with the sound they produce.
So, what is the alphabet/syllabary of Japanese?
Japanese uses “kana” to represent sounds.
Even kanji can always be re-written as kana to show their pronunciation. In modern Japanese there are two separate (but strongly related) syllabaries that make up the kana.
One is called hiragana and the other is called katakana.
Hiragana and katakana are “mirrors” of each other.
That is to say, hiragana has 46 characters, each representing one sound, and katakana also has 46 characters, with each one also representing those same sounds.
It’s kind of like how upper and lower case Latin characters represent the same thing, despite being written differently sometimes.
Of course, hiragana and katakana aren’t used in the same way as upper and lower case letters. Definitely not. They have their own unique rules and patterns of usage.
So, each kana set is made up of one of three kinds of characters.
The first five are single vowels. The last one is a single consonant. In between are 40 characters with each one repeating the same pattern: one consonant followed by one vowel.
For those of you yelling at me that there’s 48 characters each… you’re right. Sorta.
Two of the characters are outdated and hardly ever see any usage in the modern day outside of some unique branding.
In addition to all this, there’s a few special ways we can alter these characters to gain access to more sounds, but I’ll cover those a little further down.
For now, let’s zero in on each of these character sets.
Kana Origins
In the beginning there was… nothing. Japan didn’t have a true writing system until the fifth century…CE.
True, we can find some Chinese characters in artifacts from before this (stretching back to the first century), but these are all from China.
In all likelihood, the Japanese were more-or-less illiterate until the 5th century.
Originally, the Japanese would basically just write in classical Chinese. Over time, this developed into kanbun (漢文), a sort of blending of Chinese characters with Japanese structure and newly invented markings to make Chinese writing more “Japanese.”
Parallel to this was the development of man’yogana in the mid-seventh century. In man’yogana, Chinese characters would be used only to represent Japanese sounds.
It was basically a very complicated way of writing kana (I’ll delve into this a little further down).
The kana as we know them likely originated in the 8th or 9th century. These developed out of man’yogana.
The cursive form of man’yogana evolved into hiragana through a somewhat natural process.
The katakana were intentionally created in the 9th century by taking one part of a related man’yogana character and turning it into the whole character by itself to represent the sound.
The katakana were made by Buddhist priests as a Japanese phonetic gloss over difficult Chinese texts.
There’s a lot more to cover, so I’ll go over each topic in detail. But first, let’s go over the…
Hiragana: queen of the kana
I swear that sub-title isn’t sexist by my own regard. Kana originated as a “simplified” form of Japanese writing and was originally employed by noble women to write diaries and literary works.
In fact, this was so much a part of the consideration that it spawned its own word. Hiragana, today known as 平仮名, was then known as 女手 (おんなで, “onna-de”), or “women’s writing.”
The earliest Japanese literature written by women was almost entirely composed in hiragana. Eventually, even men began to adapt it to their use, mostly using it for personal letters and such.
Nowadays, it’s mixed with katakana, kanji, and romaji in prescribed ways. Hiragana is used for:
- Writing grammatical particles.
- As okurigana. That is to say, as suffix characters added to kanji to create words or inflect verbs or adjectives.
- To write entire words themselves.
- As furigana. That is to say, they are written above, or beside, kanji to show how the character is pronounced.
Hiragana have no meaning on their own—they only gain meaning through use in a sentence.
So, while を may have a particular meaning following a noun, the character of を has no intrinsic meaning. It only represents sound.
This is just like the letter “i” which can have meaning alone within a sentence (to represent the self), even though the letter “i” itself has no intrinsic meaning.
A quick interlude: Ordering the kana
The sounds of Japanese can be ordered in two official ways, just the way that the alphabet is ordered “a, b, c, d, e, etc etc etc.” The ancient form is the Iroha.
The Iroha is a poem that is said to have originated with the famous Buddhist priest Kukai (who is also said to have created much of the katakana system), though some sources dispute this, placing its creation at a later date.
Regardless, the Iroha poem uses each kana exactly one time. Here it is:
いろはにほへと
ちりぬるを
わかよたれそ
つねならむ
うゐのおくやま
けふこえて
あさきゆめみし
ゑひもせす
Iro ha nihoheto
chirinuru wo
Wa ka yo tare so
Tsune naramu
Uwi no okuyama
Kefu koete
Asaki yume mishi
Wehi mo sesu
Sharp eyed readers will notice eventually that there are two characters that seem unfamiliar, ゑ and ゐ. We’ll get to those a bit later.
Iroha kana ordering is used in a handful of instances, but none of especial importance in day-to-day life.
The other ordering system is gojuon (五十音, “go-jyuu-on”), which more closely resembles an “alphabetic ordering,” in that it has a more logical flow.
Across the top of the ordering grid are the five vowels, あいうえお (a, i, u, e, o), and, in each row below, a consonant is attached to the front to create a new sound. So, the second line is かきくけこ (ka, ki, ku, ke, ko).
The consonants go in the order K, S, T, N, H, M, Y, R, W, with a final, lone N at the end.
This will all make sense in a moment when I lay out the characters in a neat pair of charts.
Katakana: a system of many uses
As noted earlier, katakana was birthed from the need to read Buddhist scripts more easily by monks.
This script was developed by taking one part of a kanji and turning it into its own character to represent a sound. For example, 三 became ミ, 比 became ヒ, and 宇 became ウ.
For this reason, the system is called 片仮名, where 片 (“kata”) means “partial, fragmented.” In olden days, katakana had a few uses.
- To express oral testimonies, or otherwise depict that some words had been spoken.
- Vows made to deities.
- Oracles received from the gods.
- To record dreams
- Mixed with Kanji to record statements from both plaintiffs and defendants.
- Graffiti
- To write particles in Medieval texts.
- To mix with kanji, though this was rare, making up only 1-2% of all surviving documents.
Today, they are used to:
- Write loan words (コンピュータ, “konpuuta”, computer)
- Show emphasis. Similar to how italics are used in English.
- Write foreign names.
- Write anything in a non-standard way.
One important thing to note is that katakana have a one-to-one mapping with hiragana. So, ア=あ, エ=え, ウ=う, イ=い, オ=お, and so forth.
Hiragana and Katakana in all their glory
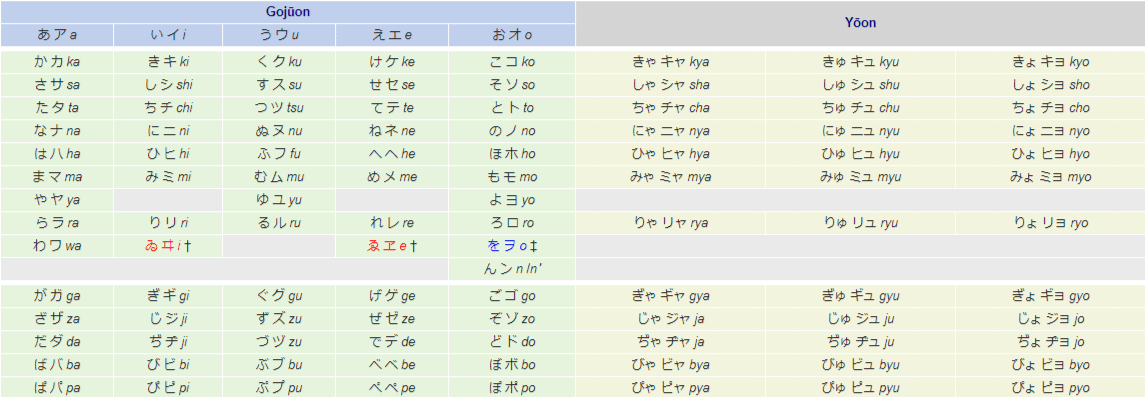
Here are the full syllabaries of hiragana and katakana. If you’re just starting out, it’s easy to distinguish them by noticing that hiragana often have “soft” edges and flow nicely, while katakana have sharp angular shapes.
Also, please note that I am including the obsolete kana, ゐ, ゑ, ヰ, and ヱ for completeness’ sake. Without further ado, here are the kana in their contemporary gojuon ordering.
HIRAGANA:
| A | I | U | E | O | |
| – | あ | い | う | え | お |
| K | こ | き | く | け | こ |
| S | さ | し | す | せ | そ |
| T | た | ち | つ | て | と |
| N | な | に | ぬ | ね | の |
| H | は | ひ | ふ | へ | ほ |
| M | ま | み | む | め | も |
| Y | や | ゆ | よ | ||
| R | ら | り | る | れ | ろ |
| W | わ | ゐ | ゑ | を | |
| ~ | ん |
KATAKANA:
| A | I | U | E | O | |
| – | ア | イ | ウ | エ | オ |
| K | カ | キ | ク | キ | コ |
| S | サ | シ | ス | セ | ソ |
| T | タ | チ | ツ | テ | ト |
| N | ナ | ニ | ヌ | ネ | ノ |
| H | ハ | ヒ | フ | ヘ | ホ |
| M | マ | ミ | ム | メ | モ |
| Y | ヤ | ユ | ヨ | ||
| R | ラ | リ | ル | レ | ロ |
| W | ワ | ヰ | ヱ | ヲ | |
| ~ | ン |
Obsolete kana: ゐ, ゑ, ヰ, and ヱ
This topic is actually pretty deep, but for the moment we’re going to just cover the characters ゐ, ゑ, ヰ, and ヱ as they are the most recently removed and therefore also the ones you are most likely to encounter.
So, to start, and to avoid any misunderstanding, these kana are only obsolete for official use in standard Japanese.
They are still used to write the indigenous languages of Ainu and the varieties of Ryukuan indigenous to Okinawa.
They’re also used in some corporate media. The most common is ヱ in the name of the popular Sapporo-produced beer, Yebisu, written ヱびす.
For those more pop-culture inclined, you’d see it in the Japanese title of Rebuild of Evangelion, aka ヱヴァンゲリヲン新劇場版.
Today, ゐ and ヰ have been replaced by い and イ. ゑ and ヱ have been replaced by え and エ. These changes officially took place in 1946.
Tiny Differences
We can even further expand the sound system with just three small changes. Collectively, these are known as yon, or 拗音 (ようおん, “you’on”).
By ever so slightly shrinking the ゃ・ャ, ゅ・ュ, and よ・ョ characters, we can gain a wealth of sounds. By attaching a kana from the “i” column to the aforementioned shrunken characters, you get a diphthong, such that キ (ki ) and ャ (ya) becomes キャ (kya), and so forth.
HIRAGANA:
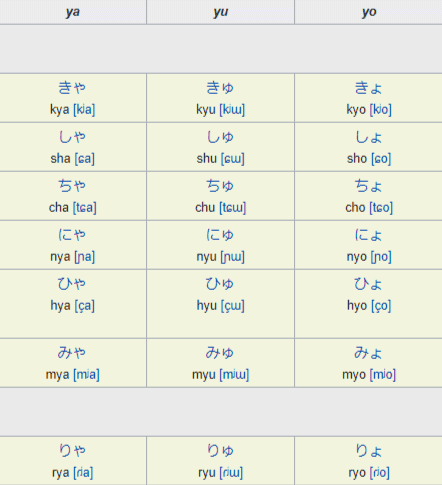
Source of the chart: https://en.wikipedia.org/wiki/Hiragana
KATAKANA:
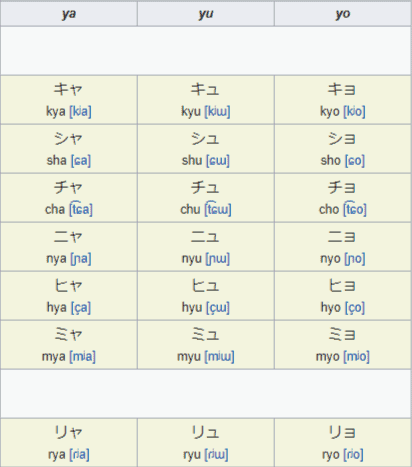
Source of the chart: https://en.wikipedia.org/wiki/Katakana
New Sounds: Dakuten
If Japanese was comprised of a measly 46 sounds, it’d be nearly unusable. As it is, it’s difficult to distinguish between the myriad homophones (leading to a culture rich in pun-based-humor).
But, we can expand the sound system. Look at the rows above. In the K, S, T, and H rows we can add little symbols that look almost like quote marks to change the sound ever so slightly.
The symbol is called a “dakuten” (濁点), a “voicing mark.” In colloquial speech it’s known as “ten-ten” (点々), or “dots.” To illustrate: か -> が. See those little marks in the upper right corner? That’s dakuten.
They take an unvoiced character and make it voiced. So, if you pronounce か (“ka”), you’ll notice the consonant isn’t “voiced.”
That is to say, your vocal cords don’t need to vibrate to make the sound. When you say が (“ga”), however, you must activate the vocal cords to make the consonant sound.
So, the K’s become G’s, the S’s become S’z, and the T’s become D’s (and sometimes Z’s depending on your romanization system).
Half Dakuten
Handakuten are an important subset of dakuten. They appear in the same place, but as tiny circles, and only go in front of “H” characters. These handakuten (aka “maru”) turn the H into a P.
は > ば > ぱ
HA > BA > PA.
Handakuten can also be applied to K-based characters to demonstrate the pronunciation of “ng.” T
his form is rarely used outside of academic situations, or in literature to show a unique way of speaking.
However, this “nasal G” sound is used heavily in the Tokyo standard dialect and can be heard regularly from broadcasters on the nightly news.
HIRAGANA:
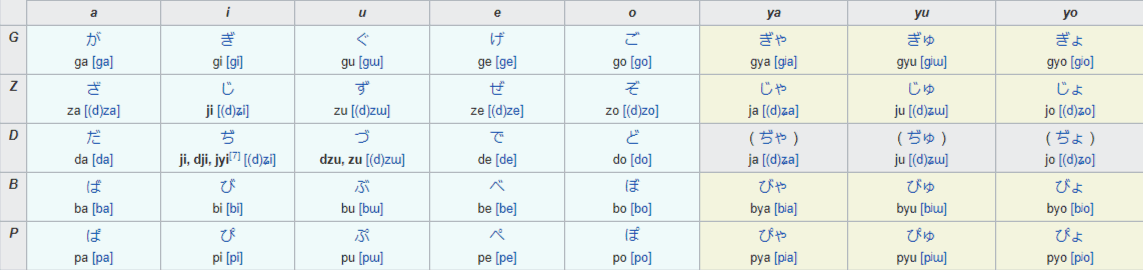
Source of the chart: https://en.wikipedia.org/wiki/Hiragana
KATAKANA: 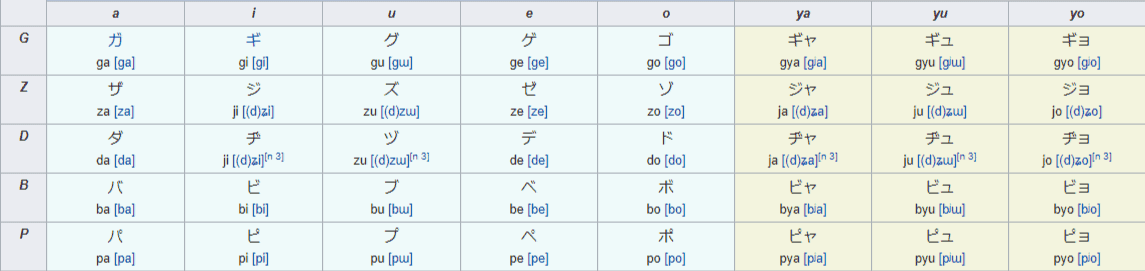
Source of the chart: https://en.wikipedia.org/wiki/Katakana
Double Tap
Separately from this, the character つ can be shrunken for grammatical purposes as well.
This shrunken character is called a 促音, a sokuon and acts to double the following consonant. It’s also called a 小さいつ (chiisai-tsu, “small tsu”) in casual language.
In technical terms, this sokuon marks a “geminate consonant.” A geminate consonant is a lengthened consonant, and counts as its own mora.
In romanization, it appears as a consonant written twice in a row. To imagine it better in English, think of the word from baseball, “inning.” That double “N” sound is a geminate consonant.
In Japanese, the sokuon is placed before the consonant to be doubled. So て (“te”) becomes って (“tte”). Let’s take a look at a few more examples:
matte > まって
kitte > きって
Pocky (pokkii) > ポッキー
One final note on this character. The sokuon is also used at the end of a statement to indicate that the speech has been cut off sharply. You’ll mostly see this in written dialogue, especially in manga.
Samurai Chōnpu
In hiragana, vowels are lengthened simply by repeating the vowel. For example:
ha > haa は >
はあ hi > hii ひ > ひい
he > hee へ > へえ
But, in katakana this is rarely the case. Instead, katakana uses a long line called a 長音符 (chou-on-pu, “chōnpu”). So, for the above examples, it would look like this:
ha > haa ハ >
ハー hi > hii ヒ >
ヒー he > hee ヘ > ヘー
That long, horizontal line is the chōnpu. In vertical Japanese writing the line becomes vertical as well.
Occasionally the chōnpu is used with hiragana, but it’s pretty rare. The only time you’re likely to encounter it is on signs for ramen which are often written らーめん.
When romanizing the long vowel, there’s three ways to do it. First, you can simply ignore it, as we often do in words that have reached common use in English, like Tokyo, Osaka, or sumo.
The other way is actually write the appropriate vowel, like Toukyou, Oosaka, or sumou. Finally, you can also write it with a macron, a line above the characters, like Tōkyō, Ōsaka, or sumō.
Repeating Yourself: Repetition Marks
An alphabet is only as useful as the rules that guide it. So, with that in mind, let’s cover a few other things that are related so that when you’re done reading, you’re ready to jump into any text and know what you’re looking at.
So, in next few sections I’m going to give a quick overview of punctuation and numerals.
First, a quick look at “iteration marks.” There are three types of iteration marks—one for kanji, hiragana, and katakana each.
These marks repeat the preceding character. So, for example, instead of writing out the exhausting 時時, we can substitute in a 々. Then, we get 時々.
While the iteration mark is used frequently with kanji, it’s not quite as commonly used with the kana. Most often you’ll see it in names, usually of places or companies.
For hiragana it’s ゝ and for katakana it’s the nearly identical ヽ. To write the name ささき (Sasaki), you can instead write さゝき.
For a name like みすず, where the dakuten appear, you would write みすゞ. Pretty nifty, eh?
Breaking Things Up: Punctuation
Next, on to the punctuation. In Japanese, most punctuation is rotated 90 degrees if it’s written vertically. So, a bracket like } would suddenly appear on its side.
One of the most important bits of punctuation is their equivalent of the period, ” 。“, which is called the 句点 (kuten), literally “phrase point.” It’s used in essentially the exact same way as a period.
Similarly, the Japanese comma has no big differences from the comma you’re already familiar with. It’s written as “、“. This one is called the 読点 (toten), literally “reading point.”
Quotation marks are done with punctuation that looks sorta like 「half brackets」. These are called 鉤括弧 (kagikakko), literally “hooked constriction bows.”
To type a quote within a quote, kind of like how we will use a mix of single and double quotes, you use a sort of hollowed-out quote mark that 『looks like this』.
These bad boys are called 二重鉤括弧 (niju-kagikakko), or double-kagikakko.
Then we get to the so-called interpunct, or, as it’s known in Japanese, the 中黒 (nakaguro). This one looks like a thick, black dot, like so: “・”.
This is a versatile character that’s used in a variety of ways. You’ll often see it separating out long, difficult katakana-English words, such as パーソナル・コンピューター (paasonaru-konpuutaa, “personal computer”), separating foreign names, and as a way to separate listed items, the way we would with a series of commas in English.
The nakaguro can be used in a variety of other situations, but the primary use will always be to show some type of separation. It’s also used as a decimal point when writing numbers in kanji.
Finally, though not in official use, standard question marks and exclamation points are used Japanese writing, especially in casual writing and fiction.
Got your number
Numerals are an important extension of our writing system, so I thought I’d cover the topic here quickly.
Usually, Japanese uses Arabic numerals, same as in English. Fairly frequently, though, Japanese also uses Kanji to write numbers out.
There’s a set of standard kanji used and then a set of formal kanji used, typically in financial statements, in order to help avoid tampering.
There’s also a set of characters used to indicate really large and really small numbers. Here’s a couple of handy charts to clear all that up for you!
STANDARD NUMBERS:
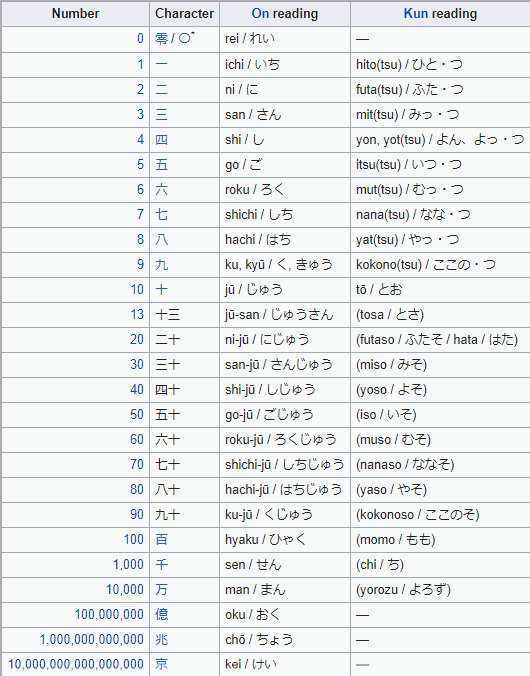
Source of the chart: https://en.wikipedia.org/wiki/Japanese_numerals
COMBINING KANJI NUMBERS: 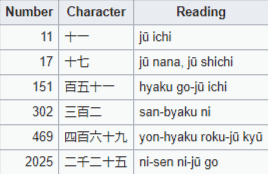
Source of the chart: https://en.wikipedia.org/wiki/Japanese_numerals
LARGE NUMBERS: 
Source of the chart: https://en.wikipedia.org/wiki/Japanese_numerals
OLD/FORMAL NUMBERS: 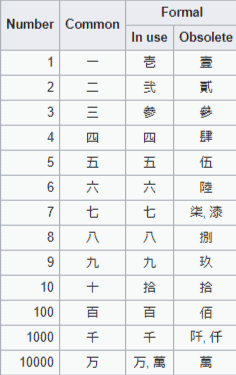
Source of the chart: https://en.wikipedia.org/wiki/Japanese_numerals
Helper Characters
Japanese characters don’t just show up in the way you’d expect. They also show up as something called furigana (振り仮名).
Furigana are placed along with other characters in order to add some information. Don’t worry, I’ll elaborate.
When text is written horizontally, the furigana appear above the main text in small print. When text is written vertically, the furigana is written to the right of the main text in small print.
Furigana is usually written in hiragana, though I’ll go over situations when it isn’t. Let’s start with the type of furigana that covers, like, 99% of all cases.
Furigana (again, usually hiragana) is usually placed above a kanji character to show how it’s pronounced. So, the character 本 might have ほん written above it in tiny text.
This type of furigana is especially useful for younger readers who might not know a kanji, but know the word when it’s written out phonetically (since, of course, a child’s listening vocabulary would be much larger than their kanji-based vocabulary).
So, in books for kids, you’ll see a lot of furigana.
Furigana is also used like this for adults, but only for unusual kanji, or unusual readings of common kanji.
Like I said, furigana get used in other ways as well. For example, if something is written in English on the page (for whatever reason), there might be katakana furigana above it to show the pronunciation.
If there’s a strange katakana-English word on the page, there might be kanji above it to explain the meaning of the word (you see this frequently in fantasy manga and novels).
Basically, any time clarification of meaning or pronunciation is required, you’ll see some kind of furigana used.
The Evolution of the Alphabet
As stated earlier, all Japanese writing began with kanji. Then, it continued with more kanji, but in a strange sort of way.
The new system of writing was called man’yogana (万葉仮名). Man’yogana look identical to kanji because, in one way, they are.
Certain kanji were used to represent a single mora (or, occasionally, two or three mora), the same way that kana do today.
That said, there was no official standard. So, from the start of its use in the 5th century, to the tail end in the 9th, almost a thousand different kanji were used to represent just 90 sounds.
These man’yogana would pass through two evolutions to give us the hiragana and katakana we know today.
Katakana, as mentioned before, developed through Buddhist monk’s shorthand, where they’d use just one part of a kanji to represent the sound.

Source of the chart: https://en.wikipedia.org/wiki/Man%27y%C5%8Dgana
Hiragana developed out of the cursive style of man’yogana. It passed through an intermediary stage in the 11th century as sogana (草仮名) before falling into a set of patterns.
In this chart, the top character is the man’yogana, the red character is the intermediary form, and the last character is the later hiragana form.
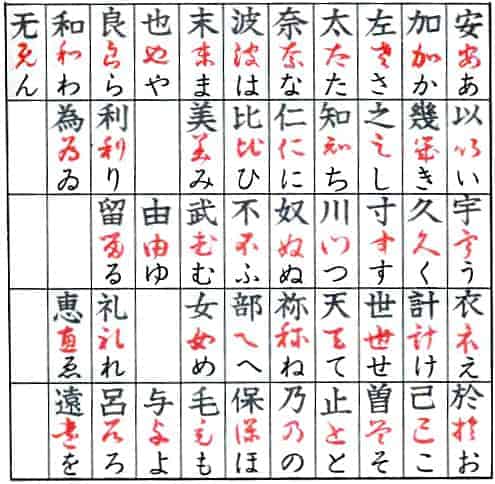
Source of the chart: https://en.wikipedia.org/wiki/Man%27y%C5%8Dgana
Nowadays, you’ll still occasionally see man’yogana and even sogana, but only to add a stylistic flair to something, such as the name of a restaurant, or to write the name of a city.
Frequently, it’s used to write “chopsticks” on chopsticks wrappers, or to write “kisoba” outside kisoba restaurants. This is akin to old timey shops writing “Ye olde” in Enlish in order to add a traditional flair.
From this, we end up at hentaigana (変体仮名). No, not that hentai.
This just means “unusual kana.” These only exist for hiragana (since they evolved naturally, unlike katakana which were chosen for their simplicity by scribes).
Hentaigana are variant forms of writing hiragana and there are hundreds of them.
Nowadays, your average Japanese person can’t read them, save a few unusually common examples (like in the above chopsticks and kisoba examples).
Related to this are kuzushi (崩し字), literally “degenerated characters.”
These are kana that are written in the old cursive style. Kanji and both kana systems were written in kuzushi.
Because these systems were written in a loose, flowing style—and before the introduction of a strictly standardized character set—the writing can be incredibly difficult to read, with many characters appearing nothing like their modern forms and/or appearing identical to other, somehow different characters on the same page!
To make things worse, there wasn’t even a standardized direction to write the characters, with writing going up, over, diagonal, and around—all on the same page.
It’s a veritable madhouse of writing. Plus, the more frequent the character, the more “degenerated” it becomes.
Since the 1900 education reforms, kuzushi is no longer taught in schools in Japan, and so the average Japanese can’t read much that’s handwritten from more than 120 years ago.
False kana: the imatto-cana
From 1690 to 1692 a German scientist by the name of Engelbert Kämpfer spent his time exploring and learning about Japan.
In his reports on the country he made several incorrect notes. He described a cohesive type of writing exclusive to the nobility which he called imatto-cana.
It turns out that he was just describing the hentaigana variants on the kana we know today.
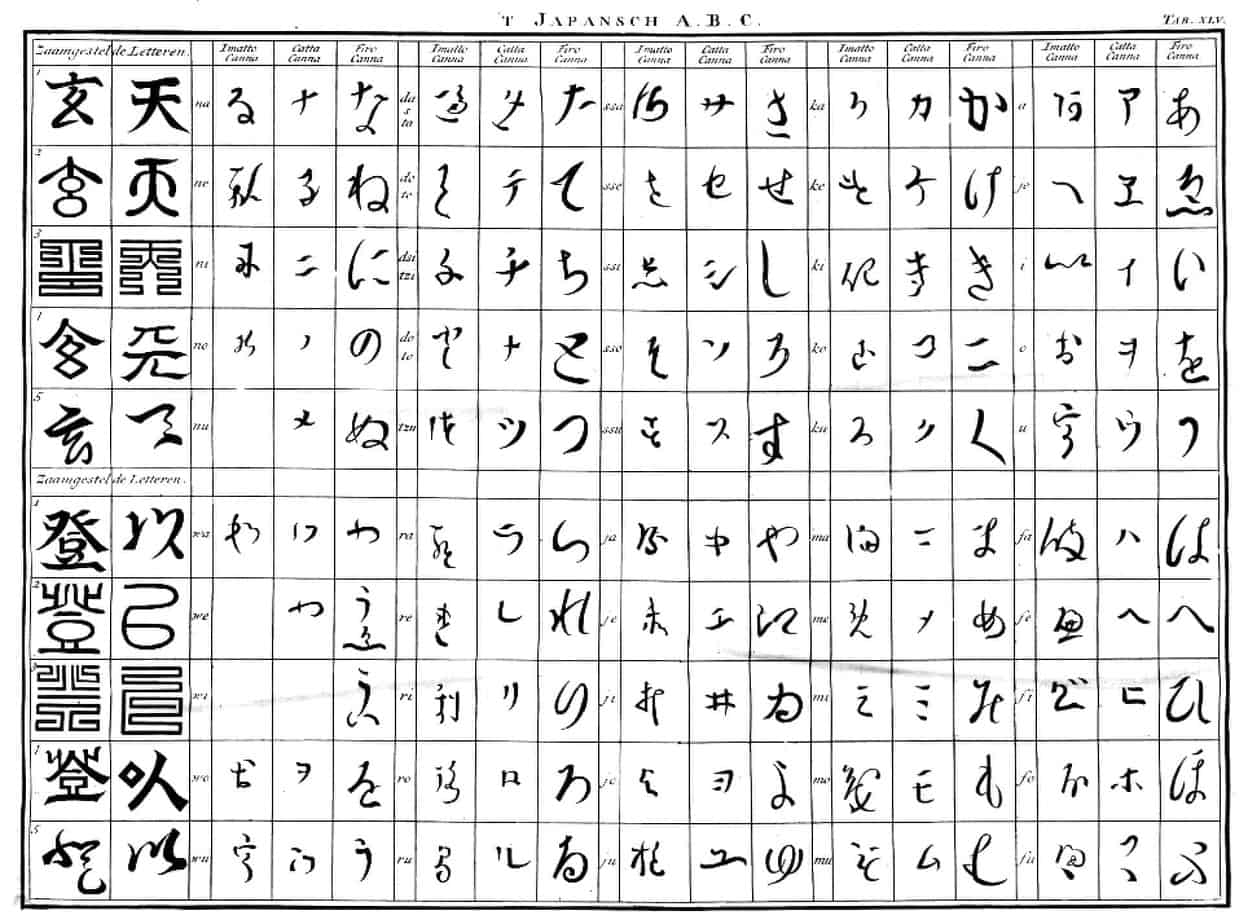
Source of the chart: https://en.wikipedia.org/wiki/Imatto-canna
Tightening up: Kana ligature
Kana ligatures are combinations of more than one character into a single unit, sort of like an alphabetic abbreviation.
One English example is the ampersand, which comes from the Latin “et” and later became the single character &.
In Japanese, most ligatures are completely obsolete, not even available to type. Two exceptions exist. ゟ is, somehow, a shortening of より. ヿ, which looks like a backwards Greek gamma, comes from, コト.
In the modern world, some creative ways have been devised to get around the lack of typable ligatures, usually by writing similar-looking kanji or kana. Two examples:
キ + モ = 托
ノ + レ = ル
I like that first example with 托 the best. It’s almost like a return to man’yogana. The character 托 would usually be pronounced “taku” and would mean “entrust” or “requesting.”
But, in its regular usage in the slangy word 托い, it becomes pronounced kimoi, and means “gross.”
So, it loses both its meaning and its original pronunciation as a kanji to represent something completely different. A neat neo-Medieval reversion, if you ask me!
There’s a similar type of character-simplification that takes place for kanji called ryakuji (略字), but that’s a bit beyond the scope of this article.
Kanji: the other alphabet
Of course, I’d be remiss if I didn’t say something about kanji in this article about the Japanese alphabet. Kanji are an indispensable part of the Japanese writing system.
There’s roughly 2300 that you need to know for average literacy, though you can pump that up to 3 or 4 thousand for those with higher education or very specialized jobs.
The most difficult kanji test in word tests on roughly 6000 kanji in total.
I wrote a whole article on kanji on this site, so check that out for a more in depth discussion on the topic!
Japanese alphabet in other languages
The Japanese kana system is used beyond just Japanese. With some small changes it is used to write the indigenous languages of Okinawa and Hokkaido, as well as Hokkien Taiwanese.
In Okinawa, typically hiragana is used with just a few small changes, such as the additional use of shrunken characters.
There are also some interesting changes made through the “New Okinawan letters” system which adds some completely new changes to otherwise familiar hiragana.
However, overall, there is no standardized system of writing Okinawan.
Ainu is written in katakana and employs a liberal use of tiny characters to extend the sound system, as well as some uses of the handakuten that wouldn’t be used in Japanese.
Taiwanese no longer uses Japanese writing. It was only prevalent during the period where Japan occupied Taiwan from 1896 until 1945.
Nowadays, only scholars study it. That said, when it was written, it used modified katakana (similar to how Ainu modifies it) along with a series of unique tone signs written beside the characters.
Modern Alphabets: Braille, morse, flags, and radio
In Japanese, braille is known as tenji (点字), or “dot characters.” Japanese braille only transcribes the kana, with no current way to write out kanji.
Each character is described by points raised on a 2×3 grid following an ingenious pattern. Check out the chart to see how it all unfolds!
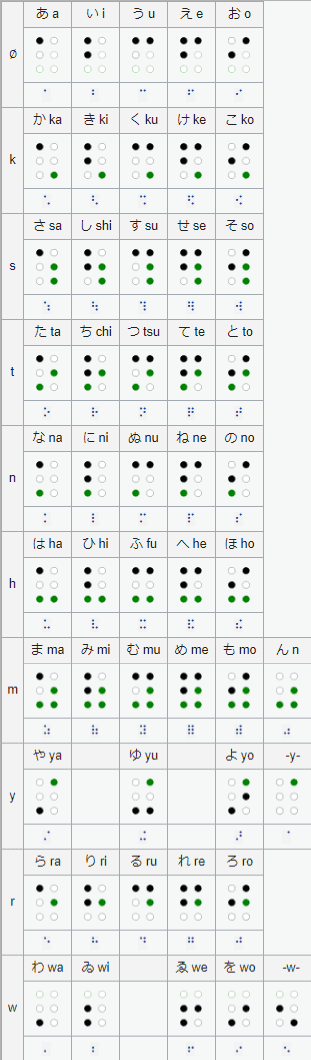
Source of the chart: https://en.wikipedia.org/wiki/Japanese_Braille
Japanese Morse code is called wabun-morus-fugo (和文モールス符号).
Like Japanese braille, it only represents Japanese kana, though I can’t tell if there’s any interesting pattern to it or not.

Source of the chart: https://en.wikipedia.org/wiki/Wabun_code
Japanese can also be encoded through semaphores, which is a form of long-distance visual telegraphy.
In the semaphore system, typically carried out with red and white flags (though anything comparable would work), specific hand positions are code for a character.
The Japanese system is different from the Latin-alphabet one.
Semaphore positions represent brush the brush stroke angles and orders of the characters as they’d be written in katakana.
Since Japanese has so many kana, most signals require two flag motions to represent each kana.
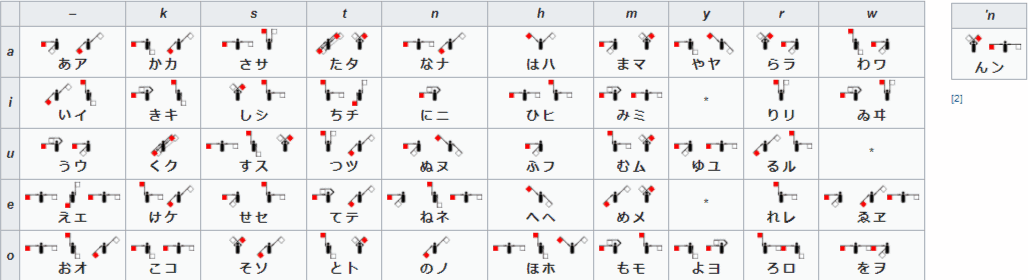
Source of the chart: https://en.wikipedia.org/wiki/Flag_semaphore#Japanese_semaphore
Finally, individual mora can be clearly communicated orally with a code word system.
This is just like the “Alpha, Bravo, Charlie, Delta, etc” system used in English. In Japanese, each kana receives its own code word.
The clarifying statement goes like so: {code word} no {kana}. So, for example, “Asahi no a.” To add (han)dakuten, you say “ni (han)dakuten.” For example, to express the sound “ga” you’d say, “kawase no ka ni dakuten.”
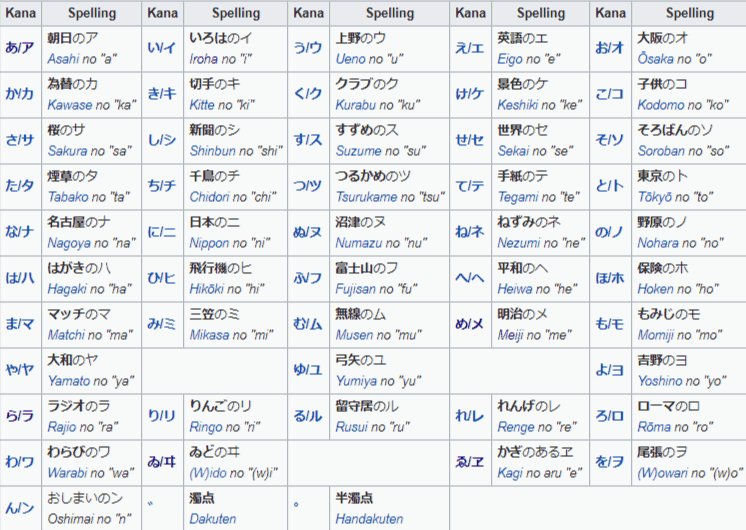
Source of the chart: https://en.wikipedia.org/wiki/Japanese_radiotelephony_alphabet
Next time won’t you sing with me…
That’s a wrap! Everything you could ever want to know about the Japanese alphabet! Go forth and read wide and well, my friends!
Related Questions
Why are there 3 alphabets in Japanese?
Part of it is an accident of history. They each evolved for different uses. Today, they’re combined and help distinguish between different types of words.
How do I learn the Japanese alphabet?
Write them over and over. Use mnemonics to help them stick in your mind. Use flash cards to help.
How many “letters” are there in Hiragana and Katakana?
There are 46 hiragana and 46 katakana. So, that’s 92 characters in total.
Is there a Japanese alphabet song?
Some people have made them up, mostly for foreign learners. So, no, there isn’t really any “official” Japanese alphabet song.

Hey fellow Linguaholics! It’s me, Marcel. I am the proud owner of linguaholic.com. Languages have always been my passion and I have studied Linguistics, Computational Linguistics and Sinology at the University of Zurich. It is my utmost pleasure to share with all of you guys what I know about languages and linguistics in general.